Professional Services, Cloud Platform Services

Stackdriver Logging can get expensive. Sometimes you don’t need to query/store all your application logs in Stackdriver, especially dev logs. Or maybe you simply don’t like Stackdriver (wink wink). On GCP you can export your logs to Google Storage Bucket automatically. Every hour there is a json file containing your logs and its metadata. What if you need just the raw logs though?
With Stackdriver Logging you pay for log ingestion. There’s also log retention of 30 days only! What if I want to store my logs for a longer period of time? What if I don’t want to pay so much for my dev logs? What if I’m using different tools for log analysis?
Stackdriver Logging has two additional services for this: Export and Exlusions. See the diagram below: 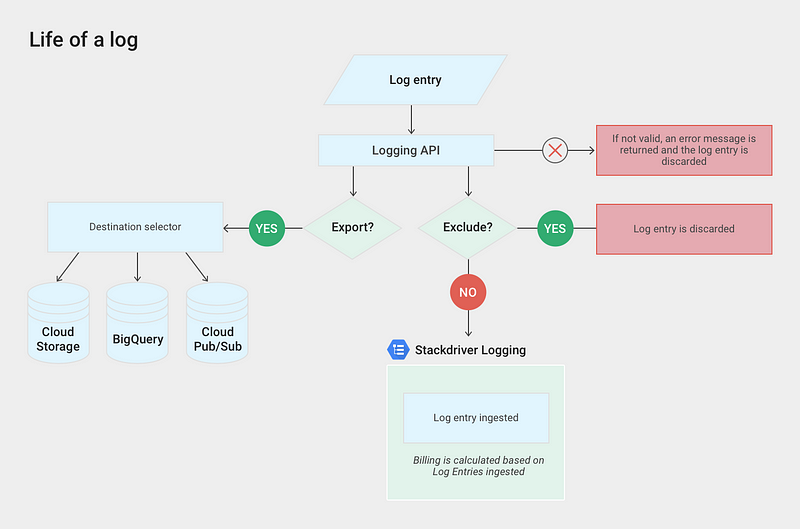
Google Cloud Platform Logging Architecture, source: https://cloud.google.com/logging/docs/export/
Stackdriver Logging Exclusions
You can exclude logs based on their resource type or write more complex exclusion queries such as:
resource.type=”container” AND labels.”container.googleapis.com/namespace_name”=”devel” AND severity > INFO
Stackdriver Logging Exports
The great thing about this architecture is, that Exports are independent from Exclusions. If I want to Export some logs to BigQuery or Bucket I can let them to be ingested by Stackdriver at the same time or Exclude them to save some money. So creating an Exclusion does not affect my Exports and that’s pretty dope.Exports are either batch or streamed. Export to bucket is batched (every hour one file named with the timestamp is created) and this can’t be changed afaik. Exports to BigQuery and Pub/Sub are streamed. You will pay for the streamed volume to BigQuery or Pub/Sub pricing accordingly. In Either case you will pay for the storage as well.Export logs to Google Storage Bucket
When you create an automatic export of your logs to a bucket, you can expect two things:Delay: around 10:10am you’ll get logs collected in time window of 9:00–10:00am and there’s nothing to guarantee that delivery time, sometimes it gets delayed even more. Not suitable for (near-)realtime log processing.Log format: each line looks like this{“insertId”:”9pxrl4ffvybrn”,”labels”:{“compute.googleapis.com/resource_name”:”fluentd-gcp-v3.1.0–2bmxq”,”container.googleapis.com/namespace_name”:”prod”,”container.googleapis.com/pod_name”:”my-app-6b495f4d8b-9l2gb”,”container.googleapis.com/stream”:”stdout”},”logName”:”projects/my-project/logs/my-app”,”receiveTimestamp”:”2019–01–26T00:00:02.198052458Z”,”resource”:{“labels”:{“cluster_name”:”prod-cluster”,”container_name”:”myapp”,”instance_id”:”4164682295655914646",”namespace_id”:”prod”,”pod_id”:”my-app-6b495f4d8b-9l2gb”,”project_id”:”my-project”,”zone”:”europe-west1-b”},”type”:”container”},”severity”:”INFO”,”textPayload”:”2019–01–26 01:00:00.788 INFO [:] DispatcherServlet:102 — Request in 3155 ms: /my/endpoint/ : 1.2.3.4 : Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)\n","timestamp":"2019-01-26T00:00:00Z"}Processing the exported logs with Cloud Functions
You can use Cloud Functions to process the exported log file in the bucket.Use the --trigger-event google.storage.object.finalize to execute the Cloud Function when this event on a particular bucket happens. This basically means that changing any file in some bucket will create this event and Cloud Function will consume that event and fire up a function to process it. For other supported event sources see the documentation.We will use nodejs-6 runtime for the Cloud Function.
'use strict';We initialized some global vars and imported libs to work with Google Cloud StorageNext, we will define some helper functions:
const path = require('path');
const fs = require('fs');
const Storage = require('@google-cloud/storage');
const readline = require('readline');
const DEST_BUCKET_NAME = process.env.DEST_BUCKET_NAME;
// Instantiates a client
const storage = Storage();
function getFileStream (file) {
if (!file.bucket) {
throw new Error('Bucket not provided. Make sure you have a "bucket" property in your request');
}
if (!file.name) {
throw new Error('Filename not provided. Make sure you have a "name" property in your request');
}
return storage.bucket(file.bucket).file(file.name).createReadStream();
}
Finally the main function:
exports.logTransformer = (event, callback) => {
const file = event.data;
const filePath = file.name; // File path in the bucket.
const contentType = file.contentType; // File content type.
const destBucket = storage.bucket(DEST_BUCKET_NAME);
// Get the file name.
const fileName = path.basename(filePath);
const options = {
input: getFileStream(file)
};
// the output is no longer application/json but text/plain
const metadata = {
contentType: "text/plain",
};
const logStream = fs.createWriteStream('/tmp/log.txt', {flags: 'w', encoding: 'utf-8'});
logStream.on('open', function() {
readline.createInterface(options)
.on('line', (line) => {
const clonedData = JSON.parse(line.replace(/\r?\n|\r/g, " "));
logStream.write(clonedData.textPayload.toString());
})
.on('close', () => {
logStream.end(function () { console.log('logstream end'); });
});
}).on('finish', () => {
// We replace the .json suffix with .txt
const thumbFileName = fileName.replace('.json','.txt');
const thumbFilePath = path.join(path.dirname(filePath), thumbFileName);
// Uploading the thumbnail.
destBucket.upload('/tmp/log.txt', {
destination: thumbFilePath,
metadata: metadata,
resumable: false
});
callback();
});
};
And that’s about it! Save that to index.js a don’t forget to include dependencies in package.json.
Deploy it
Simply deploy it via gcloud CLIDon’t forget to check the ‘View Logs’ (if you didn’t exclude them of course) for troubleshooting.SOURCE_BUCKET_NAME=my-bucket-exported-logs
DEST_BUCKET_NAME=my-bucket-exported-logs-nojson
gcloud beta functions deploy logTransformer \
--set-env-vars DEST_BUCKET_NAME="$DEST_BUCKET_NAME" \
--runtime nodejs6 \
--region europe-west1 \
--memory 128MB \
--trigger-resource "$SOURCE_BUCKET_NAME" \
--trigger-event google.storage.object.finalize
Cloud Functions come with handy out-of-box monitoring dashboard — Execution Time here
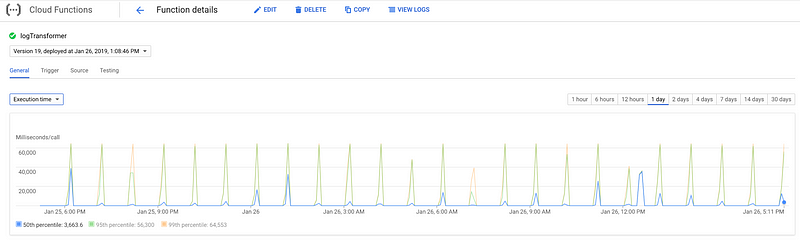
This month we’ve processed 14GiB with it so far and it’s still covered by the free tier Cloud Functions usage ❤Source code: https://github.com/marekaf/gcp-stackdriver-logging-extract-textpayloadARTICLE SOURCE https://medium.com/@marekbartik/gcp-stackdriver-logging-export-to-bucket-and-extract-textpayload-from-json-with-cloud-functions-4696798df803
FAQs
Q1: How can logs be excluded in Stackdriver Logging?
You can exclude logs based on their resource type or by writing complex queries. An example of a complex query is one that excludes Google Kubernetes Engine container logs from a specific namespace (e.g., “devel”) that have a severity greater than INFO. It is also possible to set an exclusion to discard a specific percentage of matching logs, such as 99%.
Q2: If I create a log exclusion, does that stop those logs from being exported?
No. Exports are independent of exclusions. You can create an exclusion to save money on ingestion costs while still exporting those same logs to a destination like a storage bucket or BigQuery.
Q3: What are the different types of log exports available in Stackdriver?
Exports are either batch or streamed. Exporting to a Google Storage bucket is a batch process. Exports to BigQuery and Pub/Sub are streamed.
Q4: What are the main characteristics of exporting logs to a Google Storage Bucket?
There are two key characteristics:
- Delay: The process is batched, meaning there is a delay. For example, logs collected between 9:00 AM and 10:00 AM might arrive in the bucket around 10:10 AM, and this time is not guaranteed.
- Log Format: Each log entry is delivered as a line in a specific, unchangeable JSON format containing metadata and the textPayload.
Q5: What is the recommended way to process log files after they are exported to a bucket?
You can use Cloud Functions to process the exported log files. A Cloud Function can be automatically triggered to execute whenever a new log file is finalized in the designated bucket.
Q6: How do you trigger a Cloud Function to run when a new log file is created in a bucket?
You use the trigger-event google.storage.object.finalize setting for the Cloud Function. This means that whenever a file is created or changed in the specified bucket, an event is generated, and the function is executed to process it.
Q7: How can I extract just the text message from the JSON-formatted logs exported to a bucket?
You can set up a Cloud Function that is triggered by new files in the bucket. The function's code can then parse the JSON format of each line in the log file, extract the textPayload, and save it to a new .txt file.


.jpg)